
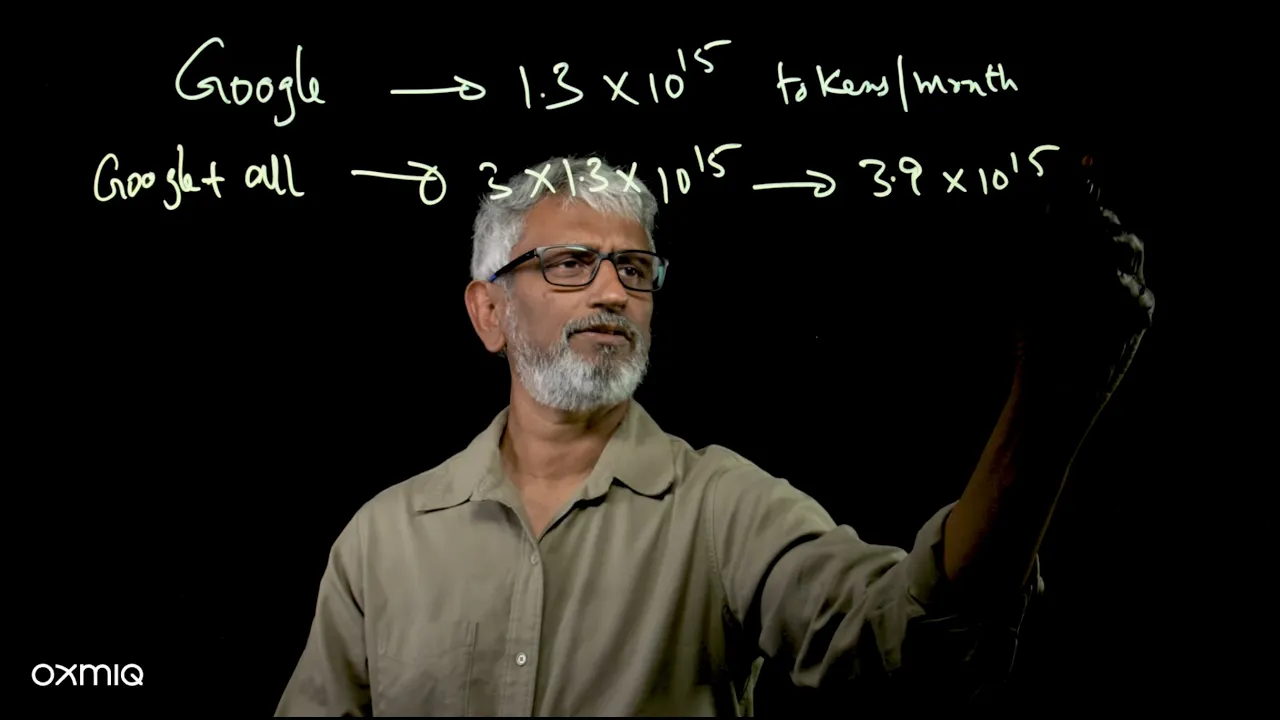
Raja Koduri on Chiplet Quilting for the Age of Inference
Raja Koduri and Chiplet Quilting for the Age of Inference
By Thomas Eugene Green
We are proud to share that Raja Koduri, CEO of Oxmiq Labs, delivered the opening keynote at the EE Times AI Everywhere event on December 10–11.
His talk, Chiplet Quilting for the Age of Inference, addressed a problem every silicon architect now faces. AI inference demand is growing faster than traditional design assumptions. Architecture decisions made today will shape performance, cost, and energy use for years.
Watch the keynote:
Why this keynote matters now
The theme of the event was AI Everywhere. Raja grounded that phrase in real numbers.
Token usage already sits in the quadrillions per month. Projected forward using conservative growth, inference demand reaches roughly 10¹⁸ tokens per month by 2030. Even at best case efficiency, this points to hundreds of gigawatts of infrastructure.
The demand signal is clear. The open question is design.
First principles still decide outcomes
Raja framed the challenge through fundamentals that matter to anyone building silicon:
Performance per dollar
Performance per watt
Flexibility across future workloads
Packaging cost
Energy to compute
Energy to move data
Energy to access memory
Physics defines the limits. Economics determines what scales.
Compute operations now cost femtojoules per bit. Data movement costs far more. Off-chip memory access dominates the energy budget. Distance matters. Memory placement matters. Packaging matters.
This is the moment where chiplets stop being optional.
Why chiplet quilting changes the equation
Post-Dennard scaling forces hard tradeoffs. Advanced nodes cost more per square millimeter. Power efficiency gains flatten. Not every function belongs on the most advanced process.
Chiplet architectures make those decisions explicit.
Chiplet quilting extends this idea by treating the system as a configurable fabric rather than a fixed layout. Compute, memory, and interconnect elements become modular. Architects gain the ability to tune for cost, power, bandwidth, and latency based on workload needs.
The benefit is flexibility without sacrificing rigor.
Tooling turns theory into practice
At Oxmiq Labs, we build tools that let teams model chiplet-based systems using real parameters.
Die size and geometry
Memory bandwidth
Interconnect bandwidth
Power consumption
Cost inputs
Picojoules per bit
Picojoules per operation
Inference workload profiles
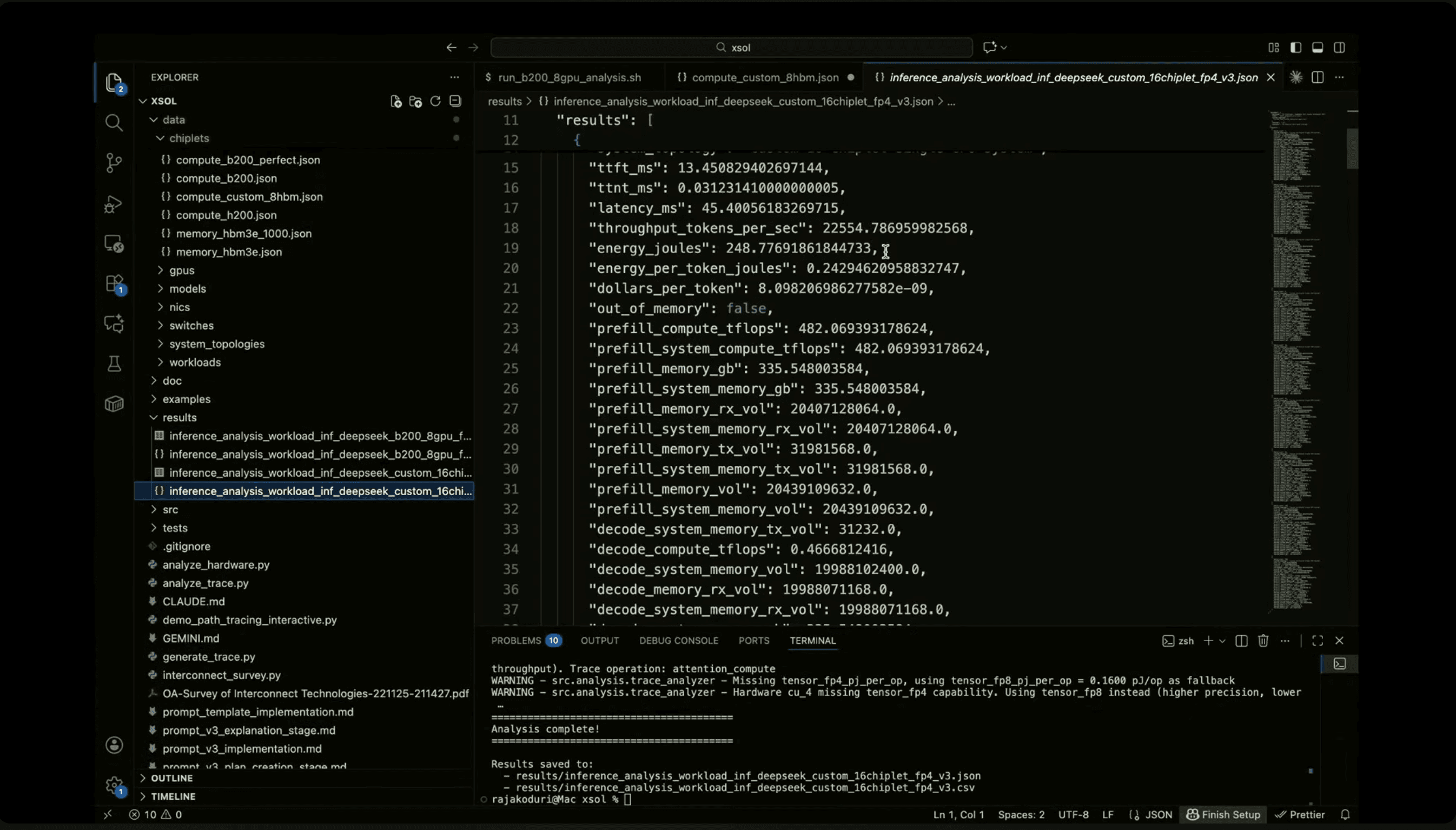
Raja walked through a reference system based on a current flagship GPU platform (NDGX B200). He then compared it with a hypothetical quilted system designed around tighter memory coupling and higher bandwidth interconnects.
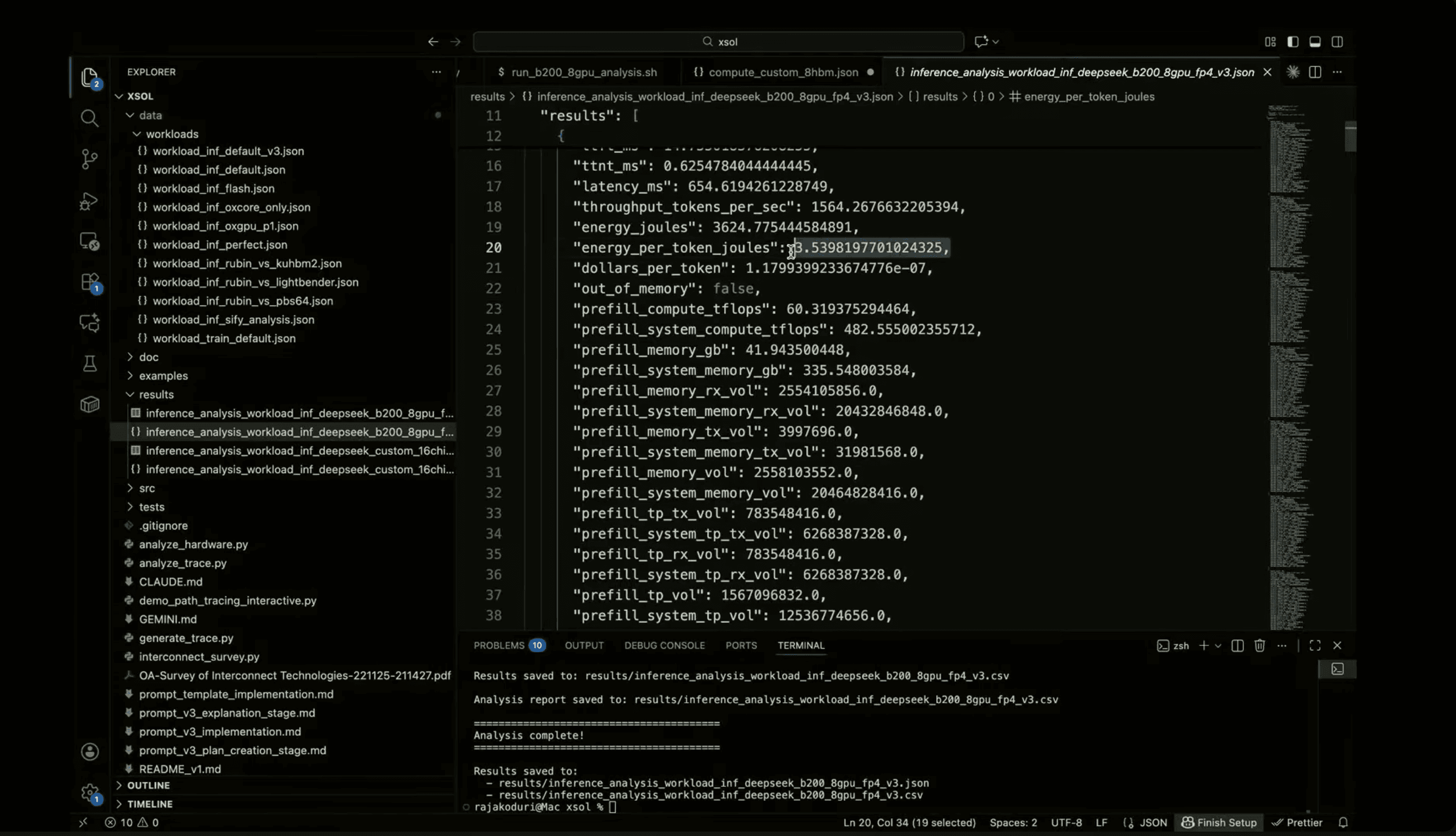
The results illustrated the direction clearly.
Order-of-magnitude gains in throughput
Order-of-magnitude reductions in energy per token
The point was not a product claim. The point was architectural leverage. When memory sits closer to compute and interconnect bottlenecks shrink, inference economics shift.
The takeaway
Raja closed with three ideas.
The age of inference has arrived.
Details at the physics level decide winners.
Chiplets are fun and offer a practical path forward.
If you are designing silicon for inference and would like to test our configuration tools, reach out to us.
There was also a Q&A afterward, where Raja got to join others to discuss the future of AI. Register to watch the discussion here.

" height="379px" id="IzMktMif4" transform="translate(0 -0.5)" width="1876.0000660911624px"/></svg>)