
Raja Koduri, who previously led GPU and semiconductor design at Apple, AMD, and Intel, is presenting a new alternative for AI computing through OXMIQ Labs. He emphasizes an integrated approach where hardware, software, and renewable energy work as one to address the soaring cost and energy challenges in today's AI infrastructure. OXMIQ's technological ambition to move beyond the NVIDIA ecosystem is reshaping the industry landscape. Building connections between India and the United States, OXMIQ envisions a next-generation computing ecosystem anchored by a triangular axis of Korea, Taiwan, and the U.S. Koduri believes that the convergence of advanced memory, packaging, and architectural innovation presents significant opportunities for Korea, a potential starting point for the next wave of competition in AI infrastructure.
To open our conversation, we would be glad to invite you to introduce yourself to our readers. As you reflect on your work across graphics, accelerated computing, and systems architecture, which formative experiences have most shaped the perspective you now bring to OXMIQ, and why did this feel like the right moment to bring the company into public view?
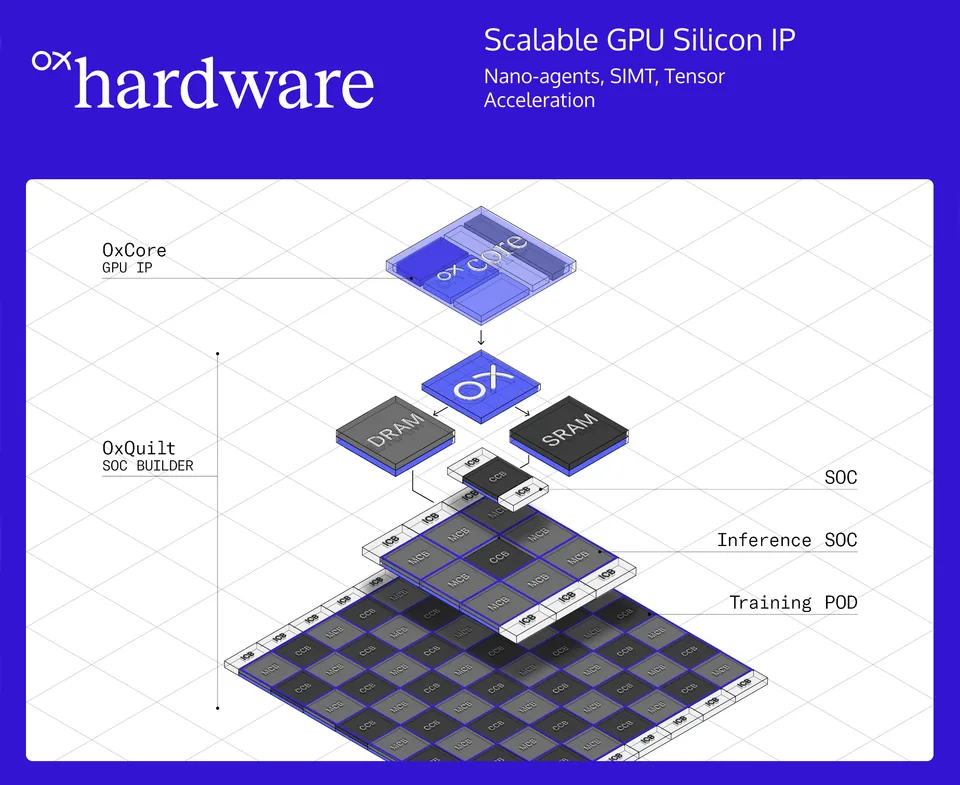
Hello my name is Raja Koduri, CEO and Founder of OXMIQ labs Inc. I've spent over three decades in the semiconductor and GPU industry, with leadership roles at ATI, AMD, Apple, and Intel. Each stop shaped me in a specific way. Apple rewired my thinking from pure technology metrics to the user's perspective. AMD, where I ran the Radeon group, taught me to innovate under brutal constraints. We planted seeds for HBM, chiplets, and ROCm that are still delivering for AMD today. Intel and the Ponte Vecchio exascale project completed my education, being inside a company that makes its own transistors, packaging, all the way to software. And the scars from all of it, the integration debt, the impossibility of clean-slate thinking inside large organizations, became the design principles behind OXMIQ.
Three years ago I also co-founded Mihira with Shobu Yarlagadda and Rajamouli, partly to get hands-on with the Python, PyTorch, and AI agent ecosystem after years of working close to the hardware. That journey is directly what led to OxPython and OxCapsule, and the realization that the CUDA compatibility problem isn't just at the bottom of the stack. It's everywhere.
We came out of stealth because we hit a specific milestone. The pieces we'd been architecting came together end to end, and I saw actual code running through the full stack for the first time. As engineers, we need to see the machine running before we claim anything. That moment happened, and the market timing is right. The demand for AI compute so far exceeds supply that there is room for an entirely new ecosystem of GPU IP licensees. We're enabling an expansion that has to happen for AI to reach the whole world.

In your recent announcement with AM Intelligence Labs, you described reliable carbon-free power as one of the most important constraints in large-scale AI infrastructure. From your vantage point, why has energy become such a decisive factor in AI compute, and what does that shift demand of the teams designing next-generation infrastructure?
A data center is fundamentally a conversion engine: photons to DC power outcomes. That DC power feeds a GPU. But the chain between those endpoints has many conversion steps on the grid that waste energy. Every conversion generates heat. Then you spend more energy cooling the heat from conversions that only existed because the generator and consumer were separate systems.
Now layer on the demand math. Google has disclosed 1.3 quadrillion monthly tokens, growing roughly 30% every few months. Extrapolate that trajectory and you reach 10^18 tokens per year by 2030, quintillion scale. Each token today costs somewhere between 1 and 10 joules. Do the arithmetic: that translates to 100 to 500 gigawatts of new infrastructure. The silicon budget alone, at current GPU costs of roughly $30,000 per kilowatt of compute, runs into trillions of dollars. When you see those numbers, you realize energy is the binding constraint, the one variable that determines whether AI scales to serve the entire world or remains concentrated among a handful of hyperscalers.
That changes what engineering teams need to look like. You can no longer have a chip team in one building and a data center team in another. At OXMIQ, our architecture reviews include energy and thermal considerations alongside transistor counts and memory bandwidth. Our software engineers understand data center operations because it shapes workload scheduling. IP designers understand chiplet integration constraints because those feed back into OxCore architecture. Every layer informs every other layer.
The target we work toward is 0.1 joules per token and $1,000 per kilowatt of compute. That is roughly a 30–50× reduction from where the industry sits today. Getting there requires shortening the distance from photon to transistor, co-locating generation and compute, and eliminating every unnecessary conversion in between. That is why the AM Intelligence Labs partnership matters. They own 50 GW of renewable generation capacity. The power is carbon-free, priced 50 to 70% below conventional data center costs. When you combine that with a systems architecture designed from scratch around those economics, you get a fundamentally different cost-per-token equation.

Your recent announcement positions India not only as a major AI market, but also as a place where large-scale AI infrastructure can be built. Given your longstanding ties to India's technology and creative communities, what makes India, and Noida in particular, especially well suited to this effort, and which local strengths do you see as most critical to the platform's success?
India is rapidly emerging as the world's second-largest market for AI usage and token consumption. The developer base is enormous, enterprise adoption is accelerating, and the digital economy is expanding at a pace very few countries can match. The question is whether India captures the value from that demand or just consumes it.
Noida brings a specific structural advantage through AM Group's integrated renewable energy platform. When you co-locate generation and compute, you eliminate transmission losses and conversion overhead. That's a cost advantage that cannot be replicated by buying power on the open market.
But India doesn't need to do everything itself. The smarter play is to partner directly with Taiwan and Korea for wafer fabrication and memory, while India builds strength in the layers where the technology is actually headed: advanced packaging, photonics, new memory architectures, and system integration. Source chiplets from TSMC or Samsung, integrate them in Indian packaging facilities, run them on Indian-licensed GPU IP. That's a partnership model, not an isolation model, and it gets India into the game much faster than trying to replicate decades of fab infrastructure from scratch.
OXMIQ has offices in both Hyderabad and Campbell. Our engineers in India work on OxCore and OxQuilt, first-principles architecture work, not outsourced design services. Over time, OxCore becomes a platform that Indian architects configure, customize, and evolve into differentiated silicon for Indian workloads. That's how you build genuine sovereignty while staying plugged into the global supply chain.

OXMIQ serves as the architecture and engineering partner for this platform. Could you elaborate on what that role involves in practical terms, and across areas such as systems architecture, interconnects, cooling, and software orchestration, which decisions proved most difficult to get right in the early design phase?
Our role spans three time horizons, and the responsibilities are different at each stage.
Near term, our job is making the right choices. The right GPUs for the target workloads, the right network configuration, the right cooling architecture, and the right software partners to orchestrate it all. These sound like procurement decisions but they're really architecture decisions, because each choice constrains every other choice downstream. Getting the initial configuration wrong is expensive to fix at gigawatt scale.
Medium term, we're optimizing the supply chain and expanding beyond GPUs into XPUs, a broader set of accelerators matched to specific workload profiles. As the platform scales and the workload mix evolves, the hardware mix needs to evolve with it. That requires a supply chain strategy that gives us flexibility rather than locking us into a single vendor's roadmap.
Long term, this is where the full OXMIQ vision comes in. We're optimizing the entire stack from photons to silicon to outcomes. Energy generation, power delivery, compute architecture, software orchestration, all designed as a single integrated system. That's when OxCore and OxQuilt become central to the platform, and the economics of the whole operation shift fundamentally.
The platform encompasses a range of service models, from AI Pods-as-a-Service to Tokens-as-a-Service. How do you anticipate customers engaging with this platform in practice, and which user profiles or workload types do you see as the most natural fit in the early stages of adoption?
The service model is evolving in lockstep with how AI itself is evolving.
In the training era, customers needed raw compute. Give me a cluster of GPUs for three months, I'll train my model. That's Pods-as-a-Service. You're renting infrastructure.
As we move into the inference era, the unit of value shifts. Customers don't want to manage GPU clusters. They want tokens. How many tokens can I get, at what latency, at what cost per million? That's Tokens-as-a-Service, and it's where much of the market is headed right now.
But I expect the next shift to be the most significant. In the agentic era, customers won't care about pods or tokens. They'll care about outcomes. Did the agent complete the task? Did it file the patent application, generate the supply chain report, diagnose the equipment failure? The metric becomes outcomes per dollar, not tokens per second. That's Outcomes-as-a-Service, and it fundamentally changes what you're optimizing for at the infrastructure layer. You're no longer maximizing throughput. You're maximizing the quality and reliability of each unit of work.
The platform is designed to support all three models, but Outcomes-as-a-Service is where we believe the market ultimately lands.
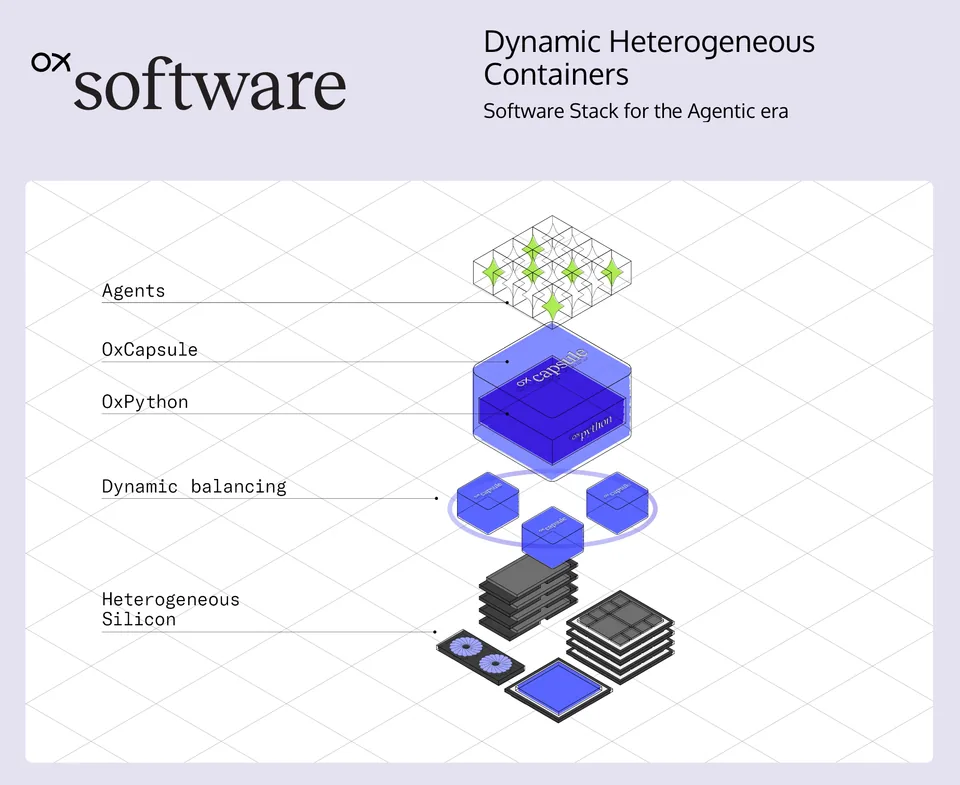
OxPython has been introduced as enabling Python-based CUDA AI applications to run on non-NVIDIA hardware without code modification or recompilation. Could you walk us through what that means in practice for development workflows, and how you see it expanding the choices available to developers and the broader hardware ecosystem?
In practice, it means a developer takes their existing Python code, their existing PyTorch models, even models pulled straight from HuggingFace with all their CUDA assumptions baked in, and runs them on non-NVIDIA hardware without touching a single line of code. No porting. No rewriting kernels. No learning a new framework. That's the goal and that's what we've demonstrated.
As I explained earlier, the CUDA compatibility challenge is an architecture problem, not just a software problem. The assumptions around NVIDIA hardware have spread into every layer of the Python and PyTorch ecosystem. Developers write code that is tied to NVIDIA and most of them don't even know it. Previous attempts to solve this, including ones I led at AMD with ROCm and at Intel with OneAPI, attacked it bottom up from the hardware layer. At OXMIQ, we took a holistic top-down view and co-architected OxPython with our hardware IP from the start.
For the broader ecosystem, this changes the equation significantly. Today, every AI hardware startup, every new accelerator company, every company bringing a novel physics approach to market faces the same wall. They have interesting silicon, but the software ecosystem doesn't work on it. OxPython removes that wall. It lets hardware innovators focus on what makes their technology special rather than spending years on the thankless job of rebuilding software compatibility from scratch. That's good for developers, who get more hardware choices. It's good for hardware companies, who can reach customers faster. And it's good for the industry, because more competition at the silicon layer is how the cost of AI compute comes down for everyone.
OXMIQ has taken a software-first, full-stack approach from the outset. What specific gaps or friction points in today's AI compute landscape does that philosophy address, and why do you believe interoperability and developer experience will prove as consequential as silicon performance in the years ahead?
The biggest friction point is one that most people misdiagnose. They say NVIDIA is ahead on software and everybody else is behind. That's not what's happening. NVIDIA is ahead on architecture. Their hardware and software were co-architected as one thing. That's why CUDA works so well on their silicon. Everyone else treats hardware and software as two separate investments, two separate teams, and then wonders why they can't catch up. I've made this mistake myself at AMD and Intel, attacking the software problem as if it were separate from the hardware problem. It's not. It's an architecture problem.
Software-first doesn't mean we deprioritize silicon. It means we prove out the software stack before the hardware shows up in silicon, because silicon design cycles are long. If you wait until your chip comes back from the fab to discover that the software ecosystem doesn't work on it, you've lost years. We built OxPython and OxCapsule to be useful today on third-party hardware. Developers and partners can use our tools now, give us feedback, and the ecosystem matures alongside the silicon rather than lagging behind it.
As for why developer experience will prove as consequential as silicon performance, just look at the numbers. There are a million models on HuggingFace today. Every one of them represents developer investment. If running that model on your hardware requires porting, rewriting, or fighting with incompatible toolchains, your silicon performance is irrelevant because nobody will use it. The best chip in the world is worthless if the developer can't get their model running on it in a day. Our goal with OxCore is exactly that. Take an open-source software stack, open-source compilers, and get up and running in days, not months.
Your recent announcement frames sustainability not as a secondary consideration, but as integral to both infrastructure design and long-term economics. As AI infrastructure continues to scale, how do you think the industry should approach energy use and sustainability in practical terms?
I don't think of sustainability as a separate consideration at all. It's physics and economics. A data center is a conversion engine. It takes electrons and turns them into tokens. The cost of those electrons is the single largest variable in the operating economics of AI at scale. If your electrons come from renewable sources at generation cost, you have a structural advantage over someone buying from the grid with all the markup, transmission losses, and conversion overhead layered on top.
The industry needs to stop treating sustainability as a compliance checkbox or an ESG branding exercise and start treating it as an engineering optimization problem. Follow the electron from source to transistor and eliminate every unnecessary conversion and every wasted joule along the way. Solar panels generate DC. GPUs consume DC. Everything in between, the AC conversion, the grid transmission, the step-down transformers, is overhead that exists because historically the generator and the consumer were separate systems. Co-locate them, shorten the path, and you get both lower cost and lower carbon at the same time. You don't have to choose.
The practical framing for the industry should be energy per token and cost per useful outcome. Drive those metrics down relentlessly. If you do that well, sustainability takes care of itself, because waste is waste whether you measure it in carbon or in dollars.

As we close, what are OXMIQ's most important medium- to long-term priorities, and what would you most want our readers to take away about the future you are working to help build?
Near term, we are scaling our teams, and working toward taping out OxCore and licensing it along with OxPython and OxCapsule to partners. In parallel, we're advancing the AM Intelligence Labs platform toward its 2027 milestone of 1 GW of renewable-powered AI compute in Noida, and growing the OxQuilt chiplet ecosystem so design teams worldwide can configure custom silicon from proven building blocks.
Longer term, OXMIQ exists to make AI compute affordable and accessible to everyone, the same way ARM and the mobile ecosystem made connectivity affordable for a billion people who could never have paid US prices. Deploying human-scale AI at current costs would require $237 trillion in CapEx. That is not a viable path. The cost per token has to come down by orders of magnitude, and that requires open, licensable compute IP, co-designed hardware and software, and infrastructure built around renewable energy.
Korea has all the key ingredients to realize the full benefits of OXMIQ's memory-centric architecture. Advanced CMOS, advanced DRAM, advanced packaging, they're all here. Very few countries in the world have that complete set of capabilities in one ecosystem. The companies, the engineers, the institutional knowledge built over decades are exactly the kind of resources that can engage with licensable GPU IP and build something truly significant on top of it. We look forward to OxCore and OxQuilt licensees and customers in Korea, and we would welcome the opportunity to build that future together.
What drives this company is building the infrastructure layer that lets a developer in Seoul, or Hyderabad, or Sao Paulo access the same compute as someone in Silicon Valley, at a price that makes sense. If we get that right, the applications people build on top will be far more interesting than anything we can imagine today.
This interview originally appeared in Alchedek.