01CUDA compatibility
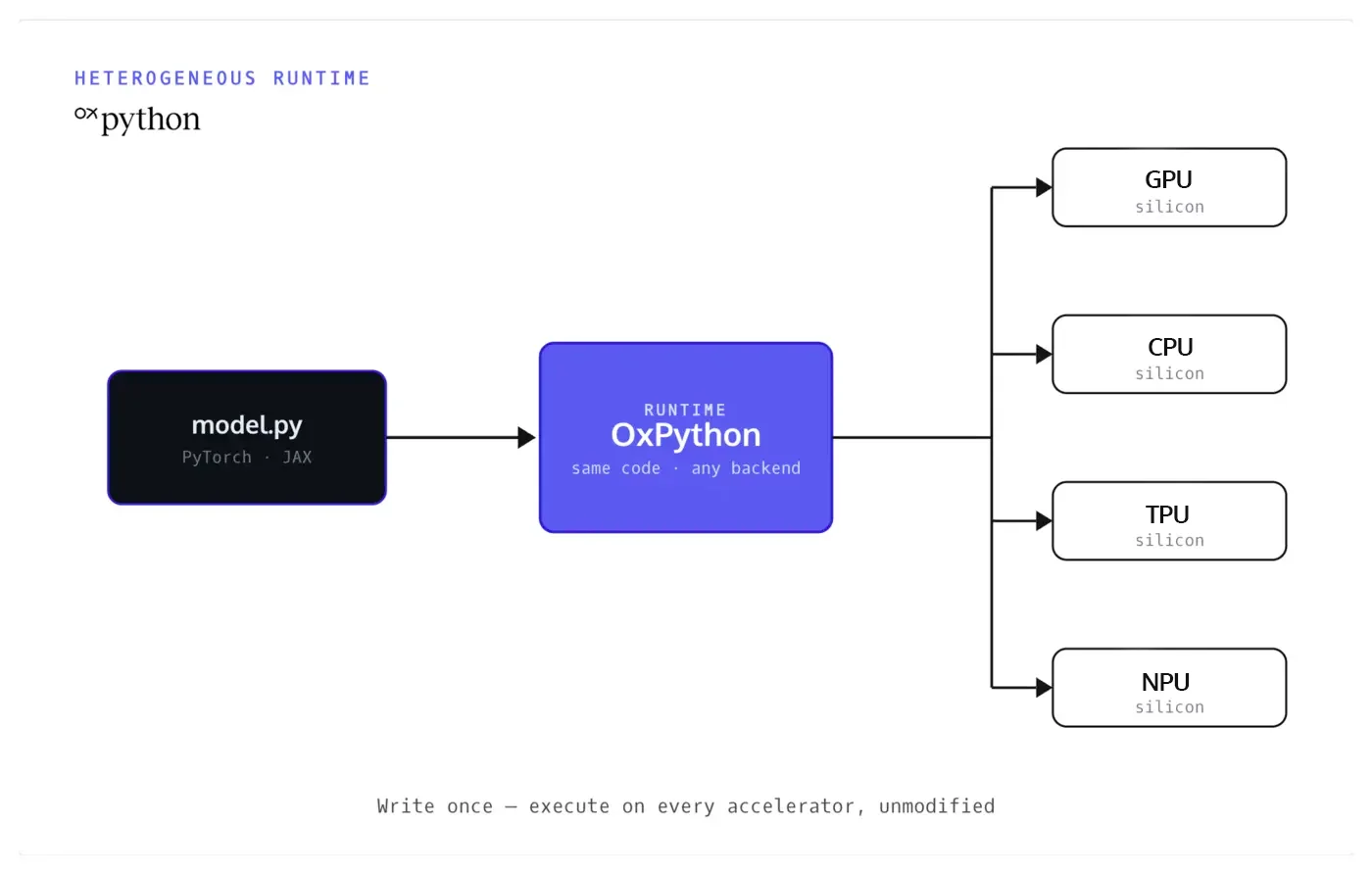
Run the world's AI, unchanged.
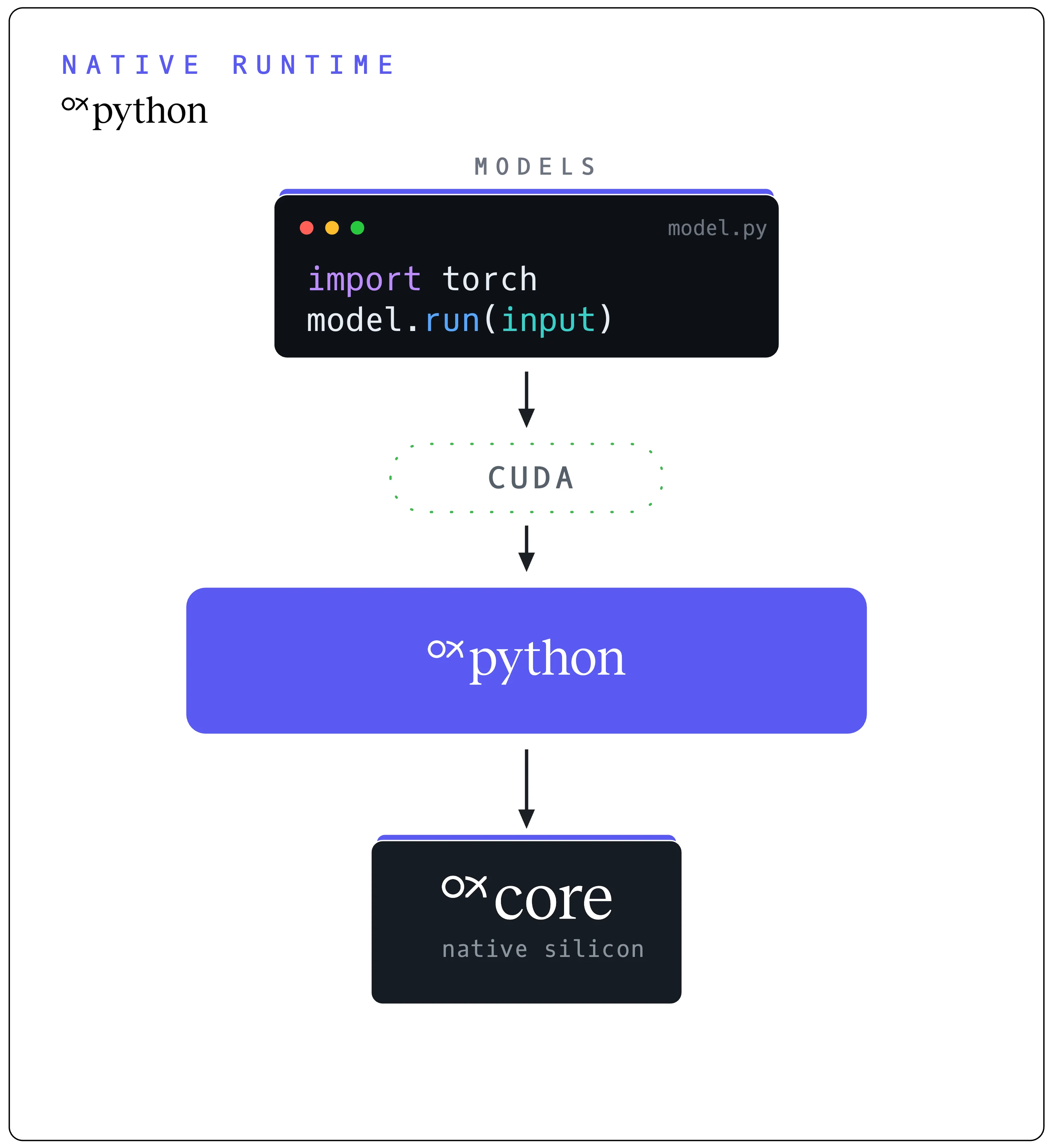
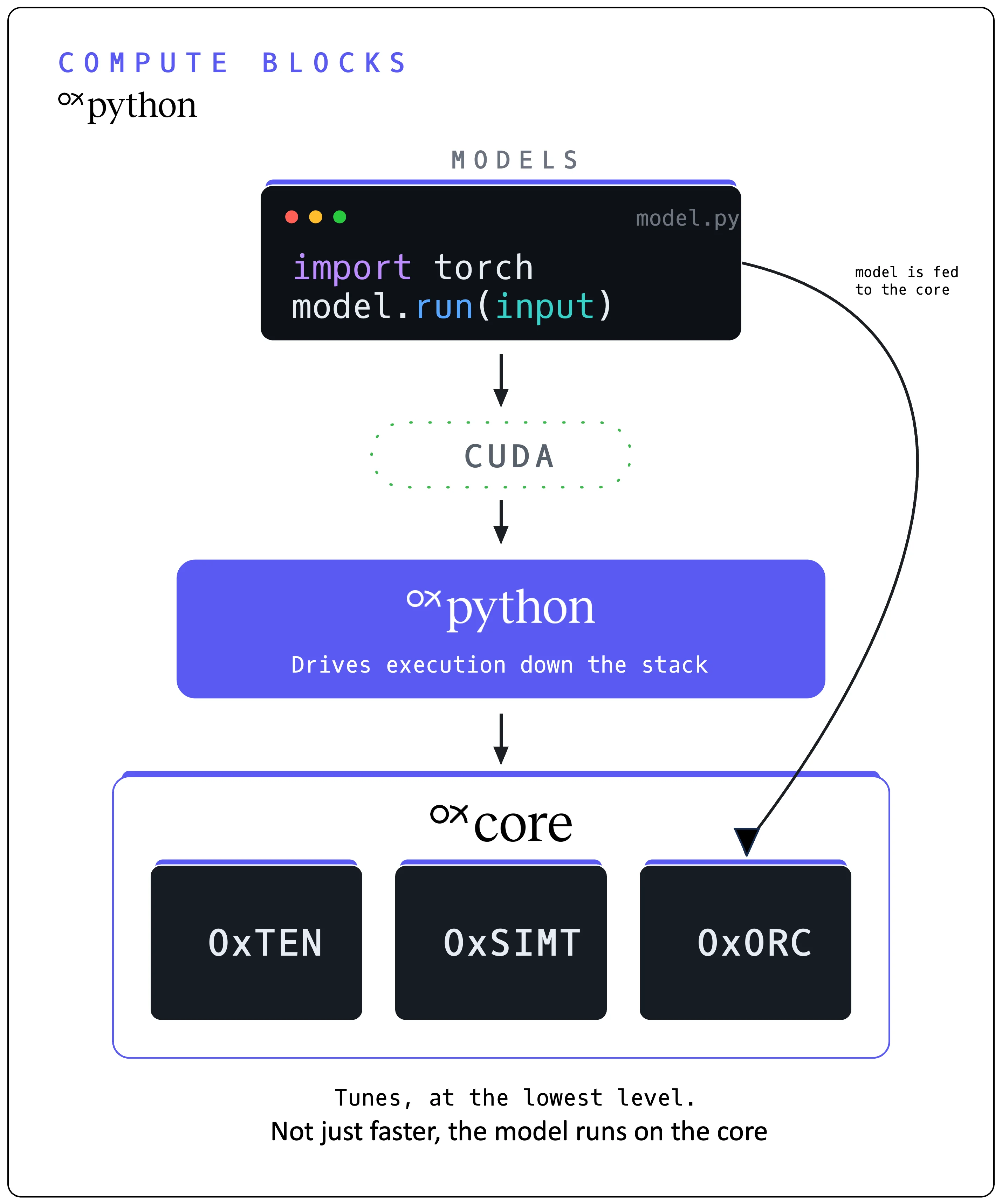
AI built for NVIDIA runs as written, with no porting and no rewrite. The industry's investment in the CUDA ecosystem carries forward instead of being thrown away. This is the on-ramp, and the proof.
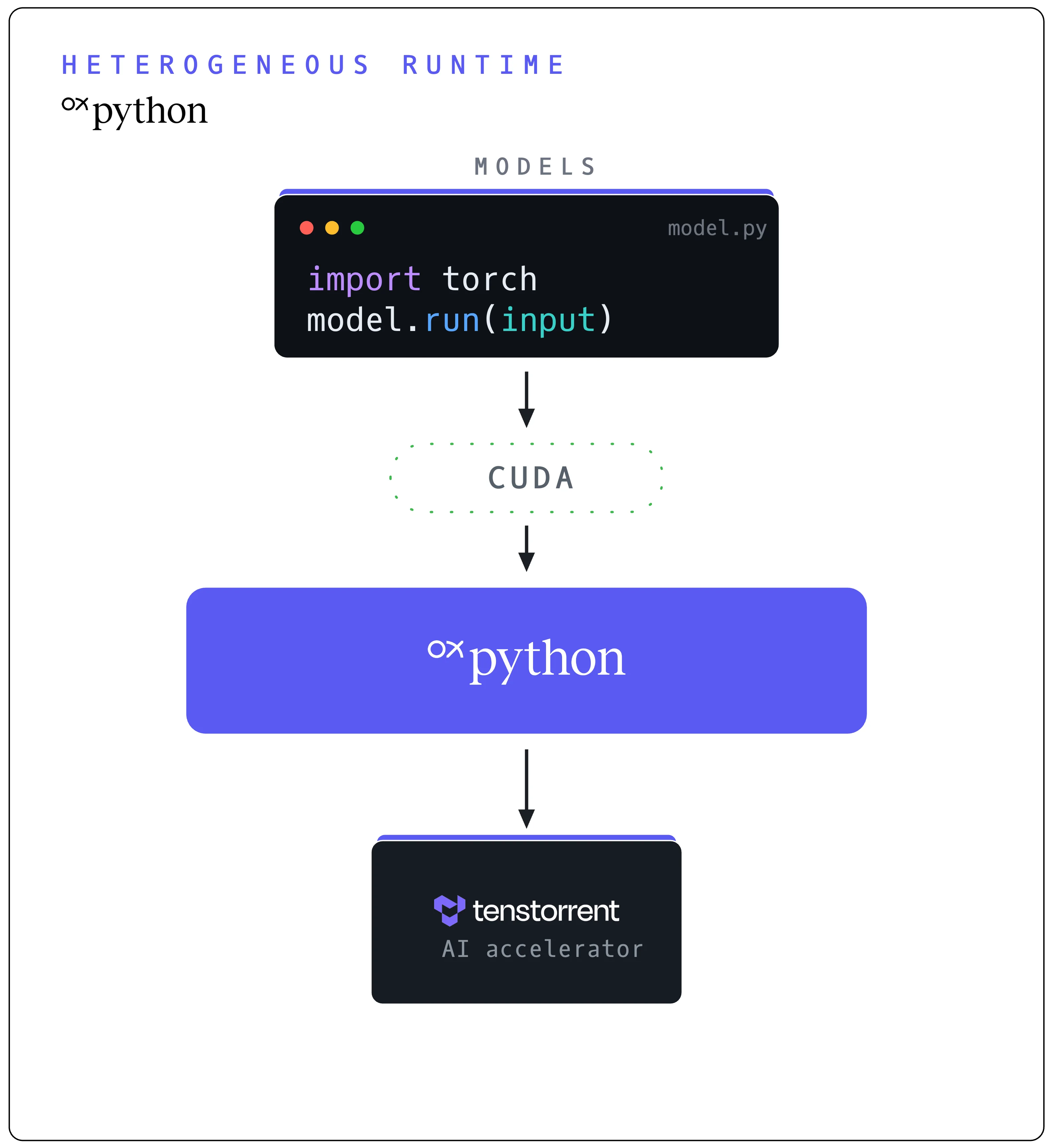
WhereTenstorrent hardware
Your AI app speaks CUDA. OxPython presents the NVIDIA interface it expects and routes the real work to Tenstorrent silicon. The app runs unchanged.