Scalable chiplet design
with advanced packaging.
Custom packaging for maximum efficiency. DRAM and SRAM stacked directly on their respective compute blocks. Every ratio tuned precisely to the workload.

Compute. Memory. Communication.
Three chiplet blocks. Each does one job well, architected to keep processing close to data. Customers compose exactly what they need.
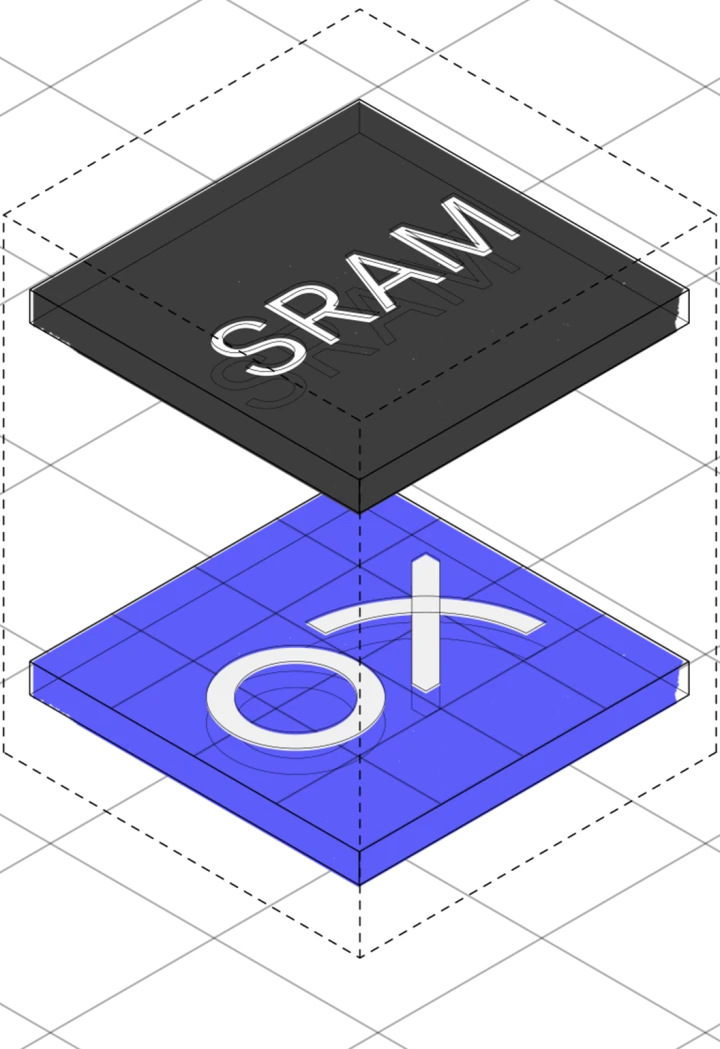
PetaFLOPS compute with large on-chip SRAM. OxCore tiles with unified scalar, vector, and tensor engines.
PetaFLOPS · On-chip SRAM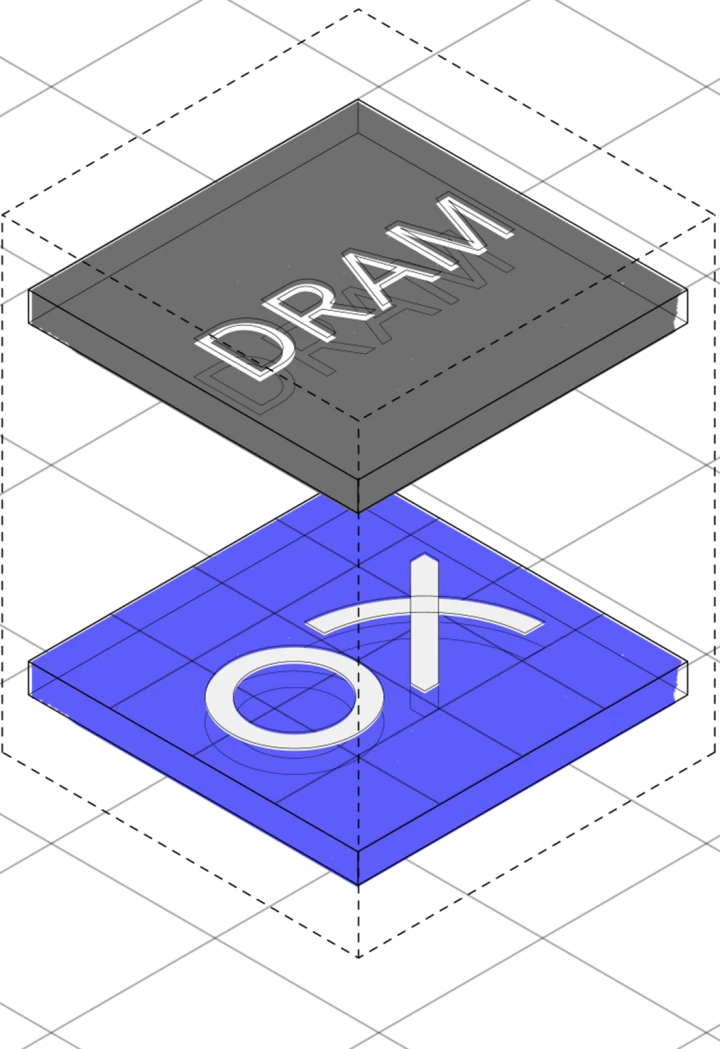
TeraFLOPS with tightly coupled memory. DRAM stacked directly on the chiplet for maximum bandwidth density.
TeraFLOPS · Tightly Coupled DRAM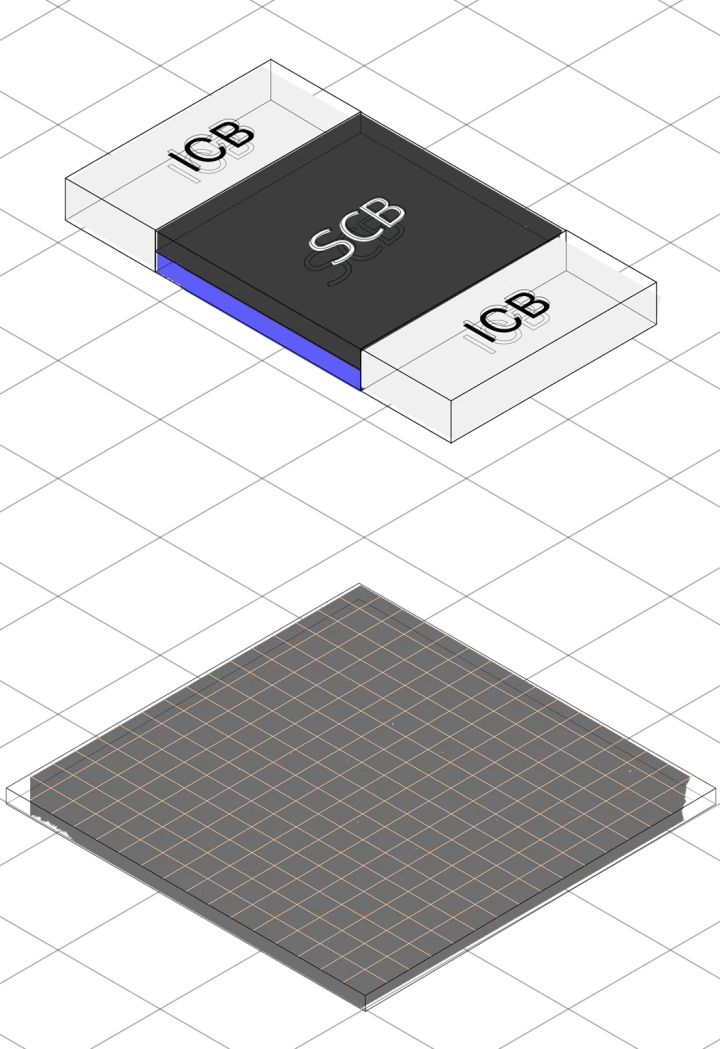
GigaFLOPS with full I/O stack. PCIe, SUE/UAL, and silicon photonics. OxFabric delivers multi-TB/s die-to-die interconnect for low-latency block-to-block communication.
GigaFLOPS · OxFabric · PCIe · SiPhAn instruction set for silicon.
OxQuilt is our scalable chiplet architecture. Instead of packing maximum compute and maximum memory onto a large monolithic chip, we went back to first principles.
Think about what RISC did to processors. Instead of one complex instruction doing everything, you get simple primitives that compose beautifully. We isolated three chiplet primitives: Compute, Memory, Communication. Each does one job well, architected to keep processing close to data. And OxFabric connects these blocks at multi-TB/s with low latency.
Then, like a well-written program built from clean abstractions, customers compose exactly what they need. Heavy inference? More DCBs for memory bandwidth, sprinkle in SCBs for just enough compute. Training at scale? Flip the ratio. Edge deployment? One SCB, one ICB, done. Same three building blocks, every configuration. Nothing wasted. Three tape-outs fund your entire product line. We are building an instruction set for silicon.
- Compute Blocks
- SCB (SRAM), DCB (DRAM), ICB (Interconnect)
- Targets
- Inference SOC, Training POD, Edge Accelerator, Mobile
- Compute
- OxCore tiles with unified scalar + vector + tensor engines
- Memory
- DRAM + SRAM tiled hierarchy, stacked on-chiplet
- Interconnect
- OxFabric — multi-TB/s die-to-die, dynamic heterogeneous balancing
- I/O
- PCIe, SUE/UAL, silicon photonics
- Runtime
- OxPython native support, OxCapsule fleet management
- Design Flow
- GUI-based chiplet configuration with workload modeling
Same blocks, every product.
Three chiplet primitives. Infinite configurations. Customers compose the exact compute, memory, and I/O ratio their workload demands.
One SCB, two ICBs. Single-digit watt inference for edge deployment. Same architecture, same software stack, smallest form factor.

Maximize memory bandwidth for large model inference. More DCBs, fewer SCBs. Optimized for tokens per second per watt.

Maximum FLOPs for distributed training. Dense SCB arrays with DCBs for weight storage and ICBs for scale-out fabric.
Chiplet quilting for the
age of inference.
Watch Raja Koduri walk through our OxQuilt configuration tool, composing chiplet blocks in comparison to NV DGX B200.
Build your silicon on